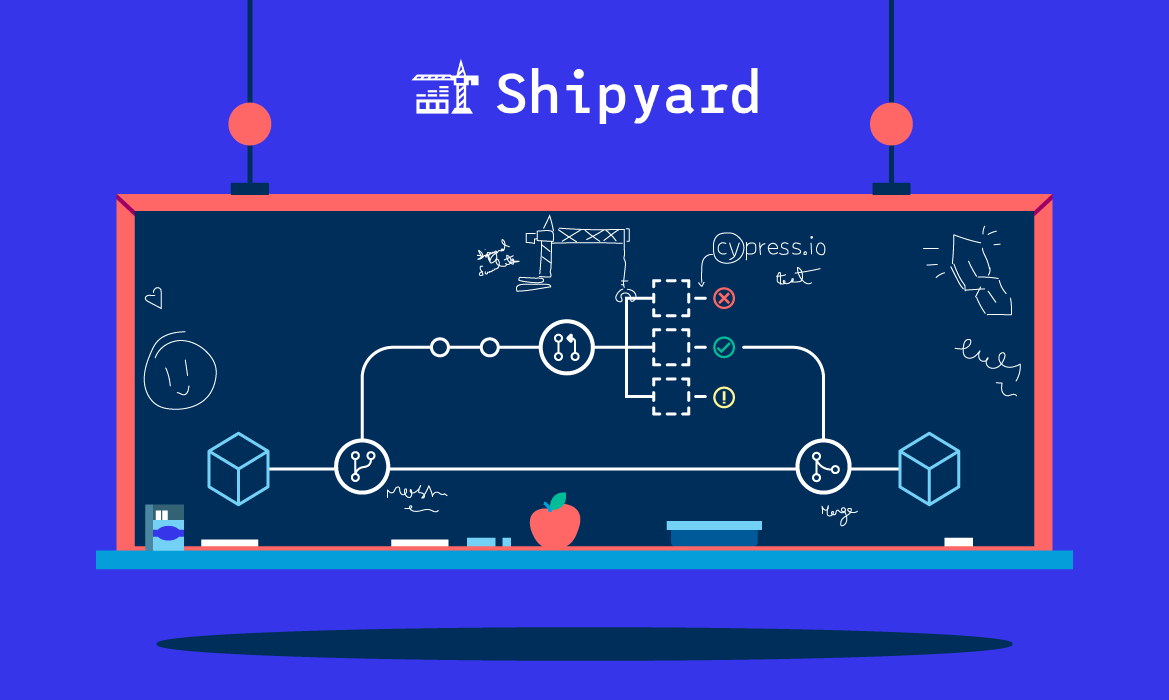
In the early days of Shipyard, we started out with the lightest weight CI pipeline possible. We started with unit tests, then introduced integration tests, and eventually added end-to-end (e2e) tests.
Before a deploy to production, we ran the e2e tests on a dedicated staging environment to make sure we weren’t going to introduce a regression.
As our organization grew in size and number of commits, we ran into a few problems:
- Regressions were discovered right before deploy, blocking releases
- Difficult to diagnose which PR was now causing failing tests on staging
- Developers had moved on to the next feature resulting in large context-switching costs
- Code reviews were happening on features that had not passed all their tests
Fortunately the product we build at Shipyard can help us solve these problems. Since Shipyard creates full-stack production-like environments on every commit, we are able to run our full test suite, including e2e tests, on every pull request.
Today we use this workflow and recommend it to our customers. In this post, we’ll share the journey to get there and how it’s benefited our team and customers who have adopted this way of working.
Testing Before Merge
Every CI tool can easily run unit tests on your PR branches. At Shipyard, our goal is to make the e2e tests just as convenient and easy to run as unit tests.
Tests should be triggered by new commits to a PR branch
This is straightforward. Cypress (our e2e tool) is popular enough to have plugins for most CI tools. We use CircleCI, and can set up Cypress relatively easily with it. A basic Cypress job might look something like this:
E2E Tests
docker:
- image: cypress/browsers:node14.17.0-chrome88-ff89
steps:
- checkout
- run:
name: "Run the e2e tests on the ephemeral environment"
command: npm install && npm run test
- store_artifacts:
path: /root/project/e2e/cypress/videos
- store_artifacts:
path: /root/project/e2e/cypress/screenshots
The CI tool should be able to handle everything itself
Tests should run programmatically. No user input. This sounds obvious, but it’s an important axiom. It will help us design our tooling. To break that down even further, there needs to be an environment to run Cypress against, and the CI tool needs to be able to determine the environment URL on its own.
Environments
Fortunately, at Shipyard, environments are what we do. To make e2e tests work, you need to be able to do four things: spin up an environment, update those environments on new commits, copy your data from environment to environment, and inform your CI where that environment actually is living.
Our main branch always has a running environment. This environment is running on Shipyard, and our data storage (Postgres) is stored on a volume. The Postgres data is “production-like” which is essential in having reliable e2e tests. We have a background process listening for GitHub hooks to identify incoming PRs. When a PR hook fires, we create a new environment using its branch, then we copy the parent volume data to the new environment.
If you use another resource, you will probably have to do some sort of bodging. For example, Heroku makes it easy to spin up new environments, but is more difficult with copying data. You will want a relatively large amount of control over the process. I would recommend a more bespoke DIY solution running on a cloud provider. If you have done all this, congratulations, you have a Shipyard competitor! I ain’t even mad. We are hiring, by the way.
Accessing Your Environment with the CI
Now that we have a running environment, our CI tool needs to be able to use it. We need some method to get the environment URL into our CI tool. Shipyard has a convenient API that returns environment URLs and the status of the environments.
curl '<https://my-api.com/environment?org_name=shipyard&repo_name=shipyard-core&branch=my-feature-branch>'
{
'ready': true,
'url': '<https://shipyard-main-pr27.dev.shipyardbuild.shipyard.host>',
}
Our actual response has added metadata, but otherwise our API is very simple.
Fortunately, the CI tool already knows several important variables needed. For CircleCI, CIRCLE_PROJECT_USERNAME CIRCLE_PROJECT_REPONAME CIRCLE_PROJECT_BRANCH are built-in environment variables. We also add our API URL as an environment variable (and an API key to protect it). Now we can hit the API endpoint from within our CI tool. We keep the code we write as simple as possible. Here is our core CI logic (in Python):
environment_data = fetch_shipyard_environment()
while not environment_data['ready']:
# Wait 15 seconds
print("Waiting for Shipyard environment...")
time.sleep(15)
# Check on the environment again
environment_data = fetch_shipyard_environment()
with open(bash_env_path, 'a') as bash_env:
bash_env.write('\\n'.join([
'export SHIPYARD_ENVIRONMENT_URL={}'.format(environment_data["url"]),
'export SHIPYARD_ENVIRONMENT_READY={}'.format(environment_data["ready"]),
]))
CircleCI’s BASH_ENV can be shared across commands. We include the code in our CircleCI config. You can do this either as a script, or straight-up bash code.
Recently we made a CircleCI orb that does just that for our API. Here’s what that looks like in our pull requests:
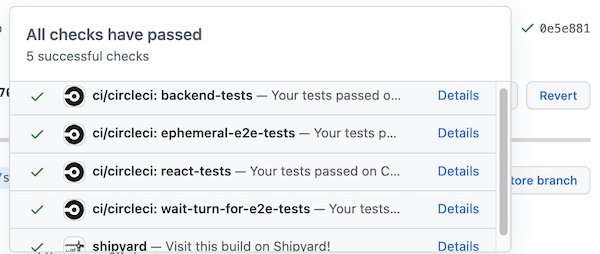
Remember the example Cypress runner for CircleCI I gave above? Here’s what our current e2e tests look like:
orbs:
cypress: cypress-io/cypress@1
node: circleci/node@4.2.0
python: circleci/python@1.0.0
shipyard: shipyard/shipyard@3
jobs:
ephemeral-e2e-tests:
docker:
- image: cypress/browsers:node14.17.0-chrome88-ff89
steps:
- checkout
- run:
name: "Gracefully exit if this is not a PR branch"
command: "[[ -z $CIRCLE_PULL_REQUEST ]] && circleci-agent task halt || echo This job is for: $CIRCLE_PULL_REQUEST"
- shipyard/fetch-shipyard-env
- run:
name: "Run the e2e tests on the ephemeral environment"
command: |
export CYPRESS_BASE_URL=${SHIPYARD_ENVIRONMENT_URL}
export CYPRESS_BYPASS_TOKEN=${SHIPYARD_BYPASS_TOKEN}
npm install && npm run test
- store_artifacts:
path: /root/project/e2e/cypress/videos
- store_artifacts:
path: /root/project/e2e/cypress/screenshots
We added a check here to prevent running against main, and the shipyard/fetch-shipyard-env step.
Review
That was a lot melded together, so let’s create a list of the breakdown. Here is each discrete step we took:
- Environment
- Existing
mainenvironment - Handle GH hooks to trigger on PR openings
- Spin up new environment
- Copy data volume to new environment
- Expose a basic API
- Existing
- CI Environment
- Use existing injected environment variables
- API request for correct URL
- Loop on request until ready
And to recap how this has affected how we work:
- Regressions are discovered at the time they’re introduced through code changes (rather than right before deploy)
- Developers have less context switching because any failures are discovered before merge, when the code is still top of mind
- Ownership of failing tests is clear, instead of trying to figure out which PR broke what
- Features have passed all their tests by the time code reviews happen
- PRs that only modify e2e tests have an immediate impact
- Editors on feature branches are affected by test changes immediately instead of during the next deploy
- If we ever have issues with our tests, we can revert until we fix the problem
Thanks for following along! It was a long journey, so make sure to approach it like a hobbit: take small steps and many lunch breaks. Until next time.